01.01.2013 Precision actuator selection
Project focus
- Compact high-precision actuators with high vibration isolation capability are defined as “low-stiffness actuators”, and their design guidelines are developed.
- Actuators for high-precision positioning are classified into three categories for analysis and understanding of vibration isolation capability.
- The effectiveness of the guidelines is experimentally demonstrated.
Description
Many applications require positioning with nanometer resolution. They include lithographic equipment for semiconductor and liquid crystal display (LCD) manufacturing and data storage devices such as hard disk drives (HDDs) and optical disk drives (ODDs) (e.g. CD/DVD/Blu-ray), as well as scientific instruments such as atomic force microscopes (AFMs). The achievable positioning resolution of these systems is typically influenced by vibrations transmitted from the floor. Dependent on the vibration sensitivity, external vibration isolation may be required, and the operation sites are restricted. For example, AFMs are typically sensitive to floor vibrations and usually used in a quiet room in spite of the use of external vibration isolators.
The sensitivity of the precision systems to floor vibrations is dependent on their actuator types, mechanical design and control design. Therefore, the relation between mechatronics designs and the floor vibration sensitivity is analyzed in this project. The aim of the analysis and the project is to develop design guidelines of compact precision positioning systems with immunity against floor vibrations, such that they can be operated in vibrational environments without external vibration isolation.
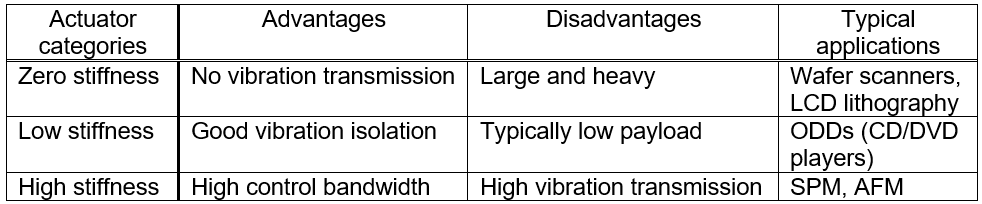
As illustrated in Fig.1, floor vibrations transmit from the base to the mover of the actuators in the precision systems. Therefore, the floor vibration sensitivity can be related to the actuator stiffness k between the mover and base. For the analysis, the high positioning systems are categorized dependent on the stiffness into three groups: high-stiffness, zero-stiffness and low-stiffness actuators, as listed in Table 1.
Simplified illustration of an actuator in precision systems
Actuator classification
High stiffness actuators
Systems with high-stiffness actuators are realized by using piezoelectric actuators, which have high stiffness between the mover and the base. Piezos have the advantages of easy miniaturization and high bandwidth. For example, piezos are mounted onto Lorentz actuators (voice coil actuators) and applied to HDDs and magnetic tape recording systems. For very high-resolution imaging, an AFM uses piezos for scanning. Piezos’ relatively high force and high stiffness are utilized in a feed drive system for machining. However, the high stiffness of the actuators strongly transmits vibrations from the floor to the mover, degrading the positioning resolution.
Zero-stiffness actuators
Systems with zero-stiffness actuators are realized with Lorentz actuators that can physically decouple the mover from the base. Such actuators are often combined with linear motors and applied to wafer scanners for lithography. Due to the zero stiffness, floor vibrations do not transmit to the mover for high-precision motion control. However, to ensure the zero stiffness, the mover need to be suspended usually by means of air feet or magnetic levitation. Consequently, these systems tend to be heavy and bulky with granite plates and air pumps for pneumatic suspension or with several sensors and actuators for magnetic levitation. Particularly the heavy mover results in a trade-off between the achievable speed and the positioning resolution, commonly known as “Mass dilemma” [Munnig Schmidt et al., “The design of High Performance Mechatronics”, 2014].
Low-stiffness actuators
In the case of low-stiffness actuators, the mover of Lorenz actuators is loosely suspended by flexures with a lowered stiffness. Consequently, the overall system can be compact unlike zero-stiffness actuators. The low stiffness is beneficial to reduce the transmission of floor vibrations, and the residual vibrations are actively isolated by means of feedback control for positioning with high resolution. Low-stiffness actuators are typically found in applications with a low payload, such as ODDs (CD, DVD and Blue-ray players). This might be because supporting a heavy mass is difficult with flexures with a low stiffness.
Table 1: Categories of high precision actuators
Definition and design guidelines of low-stiffness actuators
In comparison of the actuator categories, low-stiffness actuators have advantages that they are compact and have high vibration isolation. To develop design guidelines to construct low-stiffness actuators, they are defined as ones with the transmissibility smaller than 0 dB for all frequencies.
Based on the definition and a mechatronic system model, a design guideline of low-stiffness actuators is developed as follows:
where omega in the left and right hand side denotes the first resonant frequency of the actuator and the crossover frequency of the sensitivity function, respectively. For more details, please see [Ito et al., IEEE TMECH, 21(2), 2016].
Experimental results
In order to verify the proposed design guidelines of low-stiffness actuators, a Lorentz actuator of a CD/DVD pickup is compared as a low-stiffness actuator with a ring-bending piezo as a high-stiffness actuator. Fig. 2 is a photograph of these actuators.
Fig. 3 shows the positioning error of the actuators measured by a high-precision displacement sensor. When step-like disturbances of about 160 nm are given to the actuator base at t=0.01s, the piezo’s mover oscillates within a range of about +/- 200 nm. However, this oscillation can be successfully suppressed to +/- 10 nm by using the Lorentz actuator that satisfies the proposed design guidelines of low stiffness actuators.
In the succeeding projects (e.g. [Ito et at., Mechatronics, 44, 2017][Ito at al., Ultramicroscopy, 186, 2018]), low-stiffness actuators have been successfully applied to atomic force microscopy and high-speed long-stroke positioning, realizing nanometer-resolution positioning in vibrational environments without an external vibration isolator.

Lorentz actuator of a CD/DVD laser pickup and ring bending piezoelectric actuator, compared to verify the proposed design guidelines of the actuator classification [Ito et al., IEEE TMECH, 21(2), 2016].
Measured positioning error when step-like disturbances of about 160 nm are applied to the actuator base: (top) ring bending piezo as a high-stiffness actuator and (bottom) Lorentz actuator as a low-stiffness actuator. Please see [Ito et al., IEEE TMECH, 21(2), 2016] for more details.
Applications
- Vibration isolation
- Dual stage actuators
- Nanopositioning stages
- Data storage devices (e.g. HDDs, CD/DVD)
- In-line and on-line metrology
- Atomic force microscopy
Related publications
Journal articles
- S. Ito, S. Unger, and G. Schitter, Vibration isolator carrying atomic force microscope’s head, Mechatronics, vol. 44, p. 32–41, 2017.
[BibTex] [Download]@Article{TUW-259386, Title = {Vibration isolator carrying atomic force microscope's head}, Author = {Ito, Shingo and Unger, Severin and Schitter, Georg}, Journal = {Mechatronics}, Year = {2017}, Pages = {32--41}, Volume = {44}, Doi = {10.1016/j.mechatronics.2017.04.008}, }
- S. Ito and G. Schitter, Comparison and Classification of High-precision Actuators Based on Stiffness Influencing Vibration Isolation, IEEE/ASME Transactions on Mechatronics, vol. 21(2), 2016.
[BibTex] [Download]@Article{TUW-241933, Title = {Comparison and Classification of High-precision Actuators Based on Stiffness Influencing Vibration Isolation}, Author = {Ito, Shingo and Schitter, Georg}, Journal = {IEEE/ASME Transactions on Mechatronics}, Year = {2016}, Volume = {21(2)}, Doi = {10.1109/TMECH.2015.2478658}, Keywords = {Motion control, actuators, vibrations}, Numpages = {10}, }
- S. Ito, J. Steininger, and G. Schitter, Low-stiffness Dual Stage Actuator for Long Rage Positioning with Nanometer Resolution, Mechatronics, vol. 29, p. 46–56, 2015.
[BibTex] [Download]@Article{TUW-240765, Title = {Low-stiffness Dual Stage Actuator for Long Rage Positioning with Nanometer Resolution}, Author = {Ito, Shingo and Steininger, J{\"u}rgen and Schitter, Georg}, Journal = {Mechatronics}, Year = {2015}, Pages = {46--56}, Volume = {29}, Doi = {10.1016/j.mechatronics.2015.05.007}, }
Selected conference publications
- S. Ito, F. Cigarini, S. Unger, and G. Schitter, Flexure design for precision positioning using low-stiffness actuators, in Proceedings of the 7th IFAC Symposium on Mechatronic Systems, 2016, p. 200–205.
[BibTex]@InProceedings{TUW-251121, Title = {Flexure design for precision positioning using low-stiffness actuators}, Author = {Ito, Shingo and Cigarini, Francesco and Unger, Severin and Schitter, Georg}, Booktitle = {Proceedings of the 7th IFAC Symposium on Mechatronic Systems}, Year = {2016}, Note = {Posterpr{\"a}sentation: 7th IFAC Symposium on Mechatronic Systems {\&} 15th Mechatronics Forum International Conference, Loughborough (Vereinigte K{\"o}nigreich); 2016-09-05 -- 2016-09-08}, Pages = {200--205}, Doi = {10.1016/j.ifacol.2016.10.548}, Keywords = {Flexure, Lorentz actuator, voice coil motor, precision positioning} }
Project partners
Funding
01.01.2013 V4HRC
Human-Robot Cooperation: Perspective Sharing
Imagine a human and a robot performing a joint assembly task such as assembling a shelf. This task clearly requires a number of sequential or parallel actions and visual information about the context to be negotiated and performed in coordination by the partners.
However, human vision and machine vision differ. On one hand, computer vision systems are precise, achieve repeatable results, and are able to perceive wavelengths invisible to humans. On the other hand, sense-making of a picture or scenery can be considered a typical human trait. So how should the cooperation in a vision-based task (e.g. building something together out of Lego bricks) work for a human-robot team, if they do not have a common perception of the world?
There is a need for grounding in human-robot cooperation. In order to achieve this we have to combine the strengths of human beings (e.g. problem solving, sense making, and the ability to make decisions) with the strengths of robotics (e.g. omnivisual cameras, consistency of vision measures, and storage of vision data).
Therefore, the aim is to explore how human dyads cooperate in vision-based tasks and how they achieve grounding. The findings from human dyad will then be transferred in an adapted manner to human-robot interaction in order to inform the behavior implementation of the robot. Human and machine vision will be bridged by letting the human “see through the robot’s eyes” at identified moments, which could increase the collaboration performance. User studies using the Wizard-of-Oz technique (the robot is not acting autonomously, but is remote-controlled by a “wizard” behind the scenes) will be conducted and assessed in terms of user satisfaction. The results of human-human dyads and human-robot teams will be compared regarding performance and quality criteria (usability, user experience, and social acceptance), in order to gain an understanding of what makes human-robot cooperation perceived as satisfying for the user. As there is evidence in Human-Robot Interaction research that the cultural-background of the participants and the embodiment of the robot can influence the perception and performance of human-robot collaboration, comparison studies in the USA an Japan will be conducted to explore if this holds true for vision-based cooperation tasks in the final stage of the research undertaking. With this approach, it can be systematically explored how grounding in human-robot vision can be achieved. As such, the research proposed in this project is vital for future robotic vision projects where it is expected that robots share an environment and have to jointly perform tasks. The project follows a highly interdisciplinary approach and brings together research aspects from sociology, computer science, cognitive science, and robotics.
14.07.2011 HOBBIT
The Mutual Care Robot
Ageing has been prioritised as a key demographic element affecting the population development within the EU member states. Experts and users agree that Ambient Assisted Living (AAL) and Social and Service Robots (SSR) have the potential to become key components in coping with Europe’s demographic changes in the coming years. From all past experiences with service robots, it is evident that acceptance, usability and affordability will be the prime factors for any successful introduction of such technology into the homes of older people.
While world players in home care robotics tend to follow a pragmatic approach such as single function systems (USA) or humanoid robots (Japan, Korea), we introduce a new, more user-centred concept called “Mutual Care”: By providing a possibility for the Human to “take care” of the robot like a partner, real feelings and affections toward it will be created. It is easier to accept assistance from a robot when in certain situations, the Human can also assist the machine. In turn, older users will more readily accept the help of the HOBBIT robot. Close cooperation with institutional caregivers will enable the consortium to continuously improve acceptance and usability.
In contrast to current approaches, HOBBIT, the mutual care robot, will offer practical and tangible benefits for the user with a price tag starting below EUR 14.000 . This offers the realistic chance for HOBBIT to refinance itself in about 18-24 months (in comparison with nursing institutions or 24hr home care). In addition, HOBBIT has the potential to delay institutionalisation of older persons by at least two years which will result in a general strengthening of the competitiveness of the European economy. We will insure that the concept of HOBBIT seeds a new robotic industry segment for aging well in the European Union. The use of standardised industrial components and the participation of two leading industrial partners will ensure the exploitation of HOBBIT.
26.07.2008 Meta Mechanics
The metamechanics RoboCup@Home team was established in late 2008 at the TU Wien. It is a mixed team of the Faculty of Electrical Engineering and Information Technology and the Department of Computer Science. In 2009 the metamechanics plan to participate in Graz (World Cup) and German Open 2009 for the first time.

The team consists of a mixture of Bachelor, Master and PhD students, which are advised by professors from the university.
14.07.2008 GRASP
Emergence of Cognitive Grasping through Emulation, Introspection, and Surprise
The aim of GRASP is the design of a cognitive system capable of performing tasks in open-ended environments, dealing with uncertainty and novel situations. The design of such a system must take into account three important facts: i) it has to be based on solid theoretical basis, and ii) it has to be extensively evaluated on suitable and measurable basis, thus iii) allowing for self-understanding and self-extension.
We have decided to study the problem of object manipulation and grasping, by providing theoretical and measurable basis for system design that are valid in both human and artificial systems. We believe that this is of utmost importance for the design of artificial cognitive systems that are to be deployed in real environments and interact with humans and other artificial agents. Such systems need the ability to exploit the innate knowledge and self-understanding to gradually develop cognitive capabilities. To demonstrate the feasibility of our approach, we will instantiate, implement and evaluate our theories on robot systems with different emobodiments and levels of complexity. These systems will operate in real-world scenarios, with and without human intervention and tutoring.
GRASP will develop means for robotic systems to reason about graspable targets, to explore and investigate their physical properties and finally to make artificial hands grasp any object. We will use theoretical, computational and experimental studies to model skilled sensorimotor behavior based on known principles governing grasping and manipulation tasks performed by humans. Therefore, GRASP sets out to integrate a large body of findings from disciplines such as neuroscience, cognitive science, robotics, multi-modal perception and machine learning to achieve a core capability: Grasping any object by building up relations between task setting, embodied hand actions, object attributes, and contextual knowledge.
Goals
Develop computer vision methods to detect grasping points on any objects to grasp any object. At project end we want to show that a basket filled with everyday objects can be emptied by the robot, even if it has never seen some of the objects before. Hence it is necessary to develop the vision methods as well as link percepts to motor commands via an ontology that represents the grasping knowledge relating object properties such as shape, size, and orientation to hand grasp types and posture and the relation to the task.
Our (TUW) tasks/goals in this project are:
- [Task1] – Acquiring (perceiving, formalising) knowledge through hand-environment interaction:
The objective is to combine expectations from previous grasping experiences with the actual percepts of the present and actual grasping action. Hence we investigate a plethora of cues and features to be able to extract the set of relevant cues related to the grasping task. We will study edge structure features and grouping to objects, surface reconstruction and tracking, figure/ground segmentation, shape from edge and surfaces, recognition/classification of objects, spatio-temporal and pose relations handobject, multimodal grounding and uncertainties of geometric attributes leading to low level surprise detection and the integration or synthesis in the ontology including the combination with prediction (TUM, TUW). - [Task2] – Perceiving task relations and affordances: The objective is to exploit the set of features extracted in Task 4.1 to obtain a vocabulary of features relevant to the grasping of objects and to learn the feature relations to the potential grasping behaviours and types. These relations will form part of the grasping ontology. Furthermore, the goal is to obtain a hierarchical structure or abstraction of features, such that new objects can be related to this hierarchy. The approach sets out to obtain an asymptotic behaviour for new objects, such that early on extensions are frequently necessary, while over the course of learning more and more objects are known how to be grasped. Finally, the features will be used to propose potential actions (affordances) and are used to invoke the grasping cycle.
- [Task3] – Linking structure, affordance, action and task: The objective is to provide the necessary input to the grasping ontology, which holds in a relational graph or database the grasping experiences learned. It contains an abstraction formed over specific behaviours and sub-parts of reaching and grasping actions. It models relations and constraints to (1) the object and its properties such as size, shape and weight, to (2) perceived affordances (potentialities for actions) and grasping points, to (3) the task that is executed, e.g., grasping for pick up or to move as cup, and to (4) the context or surrounding of relevance, e.g., obstacles to circumnavigate or surfaces to place the object. It will be investigated how such a link can be efficiently established, how the plasticity of the link can be achieved to enable learning and multiple cross-references, and how this can form a hierarchy of behaviours and links to efficiently represent different grasp types/relations exploiting the vocabulary to achieve extendibility to grasp new objects.
Partners
- Kungliga Tekniska Högskolan, Stockholm, Sweden
- Universität Karlsruhe, Karlsruhe, Germany
- Technische Universität München, Munich, Germany
- Lappeenranta University of Technology, Lappeenranta, Finland
- Foundation for Research and Technology – Hellas, Greece
- Universitat Jaume I, Castellón, Spain
- Otto Bock, GmbH, Austria OB
14.07.2008 Austrian Kangaroos
Vienna has a new soccer team

Since the beginning of this year Vienna has it’s first humanoid robot soccer team called the Austrian-Kangaroos. The team composed of researchers is supported by the Automation and Control Institute and the Institute of Computer Languages Compilers and Languages Group (COMPLANG) from the TU Wien, as well as from the Institute of Computer Science from the University of Applied Sciences Technikum Wien. The teams goal is to play at the Standard Platform League at the RoboCup World Champion Ship, which will be held this year in Austria (Graz) (29.06.-05.07).
14.07.2008 CogX
Cognitive Systems that Self-Understand and Self-Extend
A specific, if very simple example of the kind of task that we will tackle is a domestic robot assistant or gopher that is asked by a human to: “Please bring me the box of cornflakes.” There are many kinds of knowledge gaps that could be present (we will not tackle all of these):
- What this particular box looks like.
- Which room this particular item is currently in.
- What cereal boxes look like in general.
- Where cereal boxes are typically to be found within a house.
- How to grasp this particular packet.
- How to grasp cereal packets in general.
- What the cornflakes box is to be used for by the human.
The robot will have to fill the knowledge gaps necessary to complete the task, but this also offers opportunities for learning. To self-extend, the robot must identify and exploit these opportunities. We will allow this learning to be curiosity driven. This provides us, within the confines of our scenario, with the ability to study mechanisms able to generate a spectrum of behaviours from purely task driven information gathering to purely curiosity driven learning. To be flexible the robot must be able to do both. It must also know how to trade-off efficient execution of the current task – find out where the box is and get it – against curiosity driven learning of what might be useful in future – find out where you can usually find cereal boxes, or spend time when you find it performing grasps and pushes on it to see how it behaves. One extreme of the spectrum we can characterise as a task focused robot assistant, the other as a kind of curious robotic child scientist that tarries while performing its assigned task in order to make discoveries and experiments. One of our objectives is to show how to embed both these characteristics in the same system, and how architectural mechanisms can allow an operator – or perhaps a higher order system in the robot – to alter their relative priority, and thus the behaviour of the robot.
Goals
The ability to manipulate novel objects detected in the environment and to predict their behaviour after a certain action is applied to them is important for a robot that can extend its own abilities. The goal is to provide the necessary sensory input for the above by exploiting the interplay between perception and manipulation. We will develop robust, generalisable and extensible manipulation strategies based on visual and haptic input. We envisage two forms of object manipulation: pushing using a “finger” containing a force-torque sensor and grasping using a parallel jaw gripper and a three-finger hand. Through coupling of perception and action we will thus be able to extract additional information about objects, e.g. weight, and reason about object properties such as empty or full.
[Task1] – Contour based shape representations. Investigate methods to robustly extract object contours using edge-based perceptual grouping methods. Develop representations of 3D shape based on contours of different views of the object, as seen from different camera positions or obtained by the robot holding and turning the object actively. Investigate how to incorporate learned perceptual primitives and spatial relations. (M1 – M12)
[Task2] – Early grasping strategies. Based on the visual sensory input extracted in Task 1, define motor representations of grasping actions for two and three-fingered hands. The initial grasping strategies will be defined by a suitable approach vector (relative pose wrt object/grasping part) and preshape strategy (grasp type). (M7 – M18)
[Task3] – Active segmentation. Use haptic information, pushing and grasping actions i) for interactive scene segmentation into meaningful objects, and ii) for extracting a more detailed model of the object (visual and haptic). Furthermore use information inside regions (surface markings, texture, shading) to complement contour information and build denser and more accurate models. (M13 – M36)
[Task4] – Active Visual Search. Survey the literature and evaluate different methods for visual object search in realistic environments with a mobile robot. Based on this survey develop a system that can detect and recognise objects in a natural (possibly simplified) environment. (M1- M24)
[Task5] – Object based spatial modeling Investigate how to include objects into the spatial representation such that properties of the available vision systems are captured and taken into account. The purpose of this task is to develop a framework that allows for a hybrid representation where objects and traditional metric spatial models can coexist. (M7 – M24)
[Task6] – Functional understanding of space Investigate by analyzing spatial models over time. (M24 – M48)
[Task7] – Grasping novel objects. Based on the object models acquired, we will investigate the scalability of the system with respect to grasping novel, previously unseen objects. We will demonstrate how the system can execute tasks that involve grasping based on the extracted sensory input (both about scene and individual objects) and taking into account its embodiment. (M25 – M48)
[Task8] – Theory revision. Given a qualitative, causal physics model, the robot should be able to revise its causal model by its match or mismatch with the qualitative object behaviour. When qualitative predictions are incorrect the system will identify where the gap is in the model, and generate hypotheses for actions that will fill in these gaps. (M37 – M48)
[Task9] – Representations of gaps in object knowledge and manipulation skills Enabling all models of objects and grasps to also represent missing knowledge is a necessary prerequisite to reason about information-gathering actions and to represent beliefs about beliefs and is therefore an ongoing task throughout the project. (M1 – 48)
Partners
- University of Birmingham BHAM United Kingdom
- Deutsches Forschungszentrum für Künstliche Intelligenz GmbH
- DFKI Germany
- Kungliga Tekniska Högskolan KTH Sweden
- Univerza v Ljubljani UL Slovenia
- Albert-Ludwigs-Universität ALU-FR Germany
26.07.2007 Robots @ Home
An Open Platform for Home Robotics

The objective of robots@home is to provide an open mobile platform for the massive introduction of robots into the homes of everyone. The innovations will be: (1) A scaleable, affordable platform in response to the different application scenarios of the four industrial partners: domotics, security, food delivery, and elderly care. (2) An embedded perception system providing multi-modal sensor data for learning and mapping of the rooms and classifying the main items of furniture. (3) A safe and robust navigation method that finally sets the case for using the platform in homes everywhere. The system is tested in four homes and at a large furniture store, e.g., IKEA. Developers as well as lay persons will show the robot around, indicate rooms and furniture and then test the capabilities by commanding to go to the refrigerator or dining table.
The scenario-driven approach is inspired by recent work in cognitive science, neuroscience and animal navigation: a hierarchical cognitive map incorporates topological, metric and semantic information. It builds on structural features observed in a newly developed dependable embedded stereo vision system complimented by time-of-flight and sonar/infrared sensors. This solution will be developed along three progressively more challenging milestones leading up to a mobile platform that learns four homes, navigates safely and heads for at least ten annotated pieces of furniture.
Goals
The milestones propose an approach with three more and more demanding scenarios:
- M12 Prototype of sizeable platform coping with basic room and floor types and first table classification,
- M24 Room layout learned by “showing the robot around”, classify main types of furniture, and then safely navigation in the home
- M36 Platforms learn four homes and safely navigate to each room and ten annotated pieces of furniture.
Partners
- ETH Zürich, CH, Prof. Roland Siegwart
- Bluebotics, CH, Dr. Nicola Tomatis
- ARC Seibersdorf, A, Dr. Wilfried Kubinger
- Legrand, F
- Nestlé Nespresso, CH
- Otto Bock, D
26.07.2006 XPERO
Experimentation with the physical world is a key to gaining insights about the real world and to develop cognitive skills necessary to exist and act in the real world. The more comprehensive and instructive the experiment, the more comprehensive and meaningful can be the insight drawn from it. Learning by experimentation has one crucial advantage over other facets of learning: the resources for learning, i.e. the learning material or training data, are basically unlimited.
In the XPERO consortium some of the top European research institutions in robotics, cognitive systems, cognitive robotics, cognitive vision, and artificial intelligence have gathered.
The overall objective of the XPERO project is to develop an embodied cognitive system, which is able to conduct experiments in the real world with the purpose of gaining new insights about the world and the objects therein and to develop and improve its own cognitive skills and overall performance.
26.07.2003 NFN
Cognitive Vision – Key Technology for Personal Assistance
Each of us might have encountered the situation to desperately search for a personal item or a location in an unknown environment. At present there is no technical solution for such an assistive system. The newly granted Joint Research Project “Cognitive Vision” attempts to find first solutions in this direction. A human shall be supported with a system that can not only find things, but that can understand the relationship between the human activities and objects involved. This understanding of new information and new knowledge is the key aspect of the cognitive approach to computer vision.

The solution proposed is based on a trans-disciplinary approach. It integrates partners from theoretical computer science (TU Graz), neuroscience (Max-Planck-Institut Tübingen), machine learning (MU Leoben), and the main computer vision groups in Austria (ACIN & PRIP at TU Wien, EMT & ICG at TU Graz and Joanneum Research Graz).
One aspect of the project is to investigate the relations of the different brain regions in visual cortex. While individual functions of these regions are relatively well studied, new methods of screening brain functions enable deeper insights that contradict present hypotheses. It could be shown that human vision profits enormously from expectations in a given situation. For example, objects in an atypical environment are spotted much more quickly than in the expected environment.
Using this analysis of the only “working” vision system we will develop computer models to describe objects under different conditions, for example, different illumination, shape, scale, clutter and occlusion, and to describe the relationships between objects and the environment. A particular emphasis is on learning these models and relationships. In the same way one shows a new object to a child, we want to relieve the user from the present exhaustive learning phases.
Another aspect of the research work is the analysis of the interrelations of the different seeing functions, namely, mechanisms to guide attention, the detection and identification of objects, the prediction of motions and intentions of the user, the integration of knowledge of the present situation, and the creation of an appropriate system reaction. The coordination of these functions is resolved using an agent/based optimisation of the utility to the system’s functioning.
The techniques devised will be implemented in prototype systems. The objective of the next three years is to track and predict where objects are moved to and where they are hidden and could be refound. A user could then ask the system where her mug is or where a specific shop is when entering unknown parts of a city. In both cases the user would be assisted and guided to the location.