14.07.2008 Austrian Kangaroos
Wien hat ein neues Fußballteam

Seit Beginn des Jahres arbeiten Wissenschaftler gemeinsam mit Studenten am ersten humanoiden Roboterfußballteam Wiens, den „Austrian-Kangaroos“. Das Institut für Automatisierungs- und Regelungstechnik und jenes für Computersprachen (COMPLANG) der Technischen Universität Wien, sowie das Institut für Informatik der FH Technikum Wien unterstützen hierbei. Um heuer erstmalig am RoboCup, der Weltmeisterschaft im Roboterfussball (29.06.-05.07. in Graz), teilnehmen zu können entwickelt das ca. zehnköpfige Team unter der Leitung von Markus Bader, Dietmar Schreiner und Alexander Hofmann mit Hochdruck an wettbewerbsfähigen Algorithmen aus den Bereichen Robotik und Künstliche Intelligenz.
Die kleinen Kicker namens NAO (60cm groß, 5kg schwer) sind standardisierte, humanoide Roboter des französischen Herstellers Aldebaran, deren individuelle Fähigkeiten und Verhalten durch die jeweiligen Teams entwickelt werden. Zur WM 2009 muss ein Team aus 3 Kickern autonom und ohne jegliche externe Unterstützung auf Torjagd gehen.
Roboterfussball hat einen hohen Unterhaltungswert, ist aber in Wirklichkeit eine ernsthafte Testumgebung für Forschung und Entwicklung in allen Bereichen. Die standardisierten humanoiden Roboter bieten eine ideale Entwicklungsplattform, die an zahlreichen internationalen Universitäten genutzt wird. So wird neben neuartigen Geh-Algorithmen und Künstlicher Intelligenz auch intensiv an verbesserter Computerbildverarbeitung und im Bereich echtzeitfähiger hochparalleler Softwarearchitekturen für Embedded Systems geforscht.
Ausgeklügelte Geh-Algorithmen lassen den Roboter im Eilschritt sicher über den unebenen Rasenteppich balancieren, wobei „echtes Laufen“ eines der angestrebten Fernziele ist. In der Bildverarbeitung muss mit veränderlichen Lichtverhältnissen und geringer Rechenleistung im Robotergehirn umgegangen werden, um den Fußball, die Mitspieler, die Gegner und die Tore zu erkennen. In der KI wird am Zusammenspiel von Reflexen, einfachen bewussten Verhalten und höheren Spielstrategien geforscht. Auf dem Weg zum Ball muss sich der kleine Kicker aller Mitspieler bewusst sein und diesen gegebenenfalls ausweichen um kein Foul zu begehen, sonst zückt der Schiedsrichter die rote Karte. Zu guter Letzt müssen die NAOs ihre vergebenen Rollen im Team wahrnehmen. So gibt es auch hier Tormann, Stürmer und Verteidiger, die nur in gutem Zusammenspiel siegreich sein werden.
14.07.2008 CogX
Cognitive Systems that Self-Understand and Self-Extend
A specific, if very simple example of the kind of task that we will tackle is a domestic robot assistant or gopher that is asked by a human to: „Please bring me the box of cornflakes.“ There are many kinds of knowledge gaps that could be present (we will not tackle all of these):
- What this particular box looks like.
- Which room this particular item is currently in.
- What cereal boxes look like in general.
- Where cereal boxes are typically to be found within a house.
- How to grasp this particular packet.
- How to grasp cereal packets in general.
- What the cornflakes box is to be used for by the human.
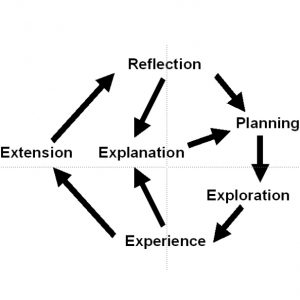
The robot will have to fill the knowledge gaps necessary to complete the task, but this also offers opportunities for learning. To self-extend, the robot must identify and exploit these opportunities. We will allow this learning to be curiosity driven. This provides us, within the confines of our scenario, with the ability to study mechanisms able to generate a spectrum of behaviours from purely task driven information gathering to purely curiosity driven learning. To be flexible the robot must be able to do both. It must also know how to trade-off efficient execution of the current task – find out where the box is and get it – against curiosity driven learning of what might be useful in future – find out where you can usually find cereal boxes, or spend time when you find it performing grasps and pushes on it to see how it behaves. One extreme of the spectrum we can characterise as a task focused robot assistant, the other as a kind of curious robotic child scientist that tarries while performing its assigned task in order to make discoveries and experiments. One of our objectives is to show how to embed both these characteristics in the same system, and how architectural mechanisms can allow an operator – or perhaps a higher order system in the robot – to alter their relative priority, and thus the behaviour of the robot.
Goals
The ability to manipulate novel objects detected in the environment and to predict their behaviour after a certain action is applied to them is important for a robot that can extend its own abilities. The goal is to provide the necessary sensory input for the above by exploiting the interplay between perception and manipulation. We will develop robust, generalisable and extensible manipulation strategies based on visual and haptic input. We envisage two forms of object manipulation: pushing using a „finger“ containing a force-torque sensor and grasping using a parallel jaw gripper and a three-finger hand. Through coupling of perception and action we will thus be able to extract additional information about objects, e.g. weight, and reason about object properties such as empty or full.
[Task1] – Contour based shape representations. Investigate methods to robustly extract object contours using edge-based perceptual grouping methods. Develop representations of 3D shape based on contours of different views of the object, as seen from different camera positions or obtained by the robot holding and turning the object actively. Investigate how to incorporate learned perceptual primitives and spatial relations. (M1 – M12)
[Task2] – Early grasping strategies. Based on the visual sensory input extracted in Task 1, define motor representations of grasping actions for two and three-fingered hands. The initial grasping strategies will be defined by a suitable approach vector (relative pose wrt object/grasping part) and preshape strategy (grasp type). (M7 – M18)
[Task3] – Active segmentation. Use haptic information, pushing and grasping actions i) for interactive scene segmentation into meaningful objects, and ii) for extracting a more detailed model of the object (visual and haptic). Furthermore use information inside regions (surface markings, texture, shading) to complement contour information and build denser and more accurate models. (M13 – M36)
[Task4] – Active Visual Search. Survey the literature and evaluate different methods for visual object search in realistic environments with a mobile robot. Based on this survey develop a system that can detect and recognise objects in a natural (possibly simplified) environment. (M1- M24)
[Task5] – Object based spatial modeling Investigate how to include objects into the spatial representation such that properties of the available vision systems are captured and taken into account. The purpose of this task is to develop a framework that allows for a hybrid representation where objects and traditional metric spatial models can coexist. (M7 – M24)
[Task6] – Functional understanding of space Investigate by analyzing spatial models over time. (M24 – M48)
[Task7] – Grasping novel objects. Based on the object models acquired, we will investigate the scalability of the system with respect to grasping novel, previously unseen objects. We will demonstrate how the system can execute tasks that involve grasping based on the extracted sensory input (both about scene and individual objects) and taking into account its embodiment. (M25 – M48)
[Task8] – Theory revision. Given a qualitative, causal physics model, the robot should be able to revise its causal model by its match or mismatch with the qualitative object behaviour. When qualitative predictions are incorrect the system will identify where the gap is in the model, and generate hypotheses for actions that will fill in these gaps. (M37 – M48)
[Task9] – Representations of gaps in object knowledge and manipulation skills Enabling all models of objects and grasps to also represent missing knowledge is a necessary prerequisite to reason about information-gathering actions and to represent beliefs about beliefs and is therefore an ongoing task throughout the project. (M1 – 48)
Partners
- University of Birmingham BHAM United Kingdom
- Deutsches Forschungszentrum für Künstliche Intelligenz GmbH
- DFKI Germany
- Kungliga Tekniska Högskolan KTH Sweden
- Univerza v Ljubljani UL Slovenia
- Albert-Ludwigs-Universität ALU-FR Germany
26.07.2007 Robots @ Home
An Open Platform for Home Robotics

The objective of robots@home is to provide an open mobile platform for the massive introduction of robots into the homes of everyone. The innovations will be: (1) A scaleable, affordable platform in response to the different application scenarios of the four industrial partners: domotics, security, food delivery, and elderly care. (2) An embedded perception system providing multi-modal sensor data for learning and mapping of the rooms and classifying the main items of furniture. (3) A safe and robust navigation method that finally sets the case for using the platform in homes everywhere. The system is tested in four homes and at a large furniture store, e.g., IKEA. Developers as well as lay persons will show the robot around, indicate rooms and furniture and then test the capabilities by commanding to go to the refrigerator or dining table.
The scenario-driven approach is inspired by recent work in cognitive science, neuroscience and animal navigation: a hierarchical cognitive map incorporates topological, metric and semantic information. It builds on structural features observed in a newly developed dependable embedded stereo vision system complimented by time-of-flight and sonar/infrared sensors. This solution will be developed along three progressively more challenging milestones leading up to a mobile platform that learns four homes, navigates safely and heads for at least ten annotated pieces of furniture.
Goals
The milestones propose an approach with three more and more demanding scenarios:
- M12 Prototype of sizeable platform coping with basic room and floor types and first table classification,
- M24 Room layout learned by “showing the robot around”, classify main types of furniture, and then safely navigation in the home
- M36 Platforms learn four homes and safely navigate to each room and ten annotated pieces of furniture.
Partners
- ETH Zürich, CH, Prof. Roland Siegwart
- Bluebotics, CH, Dr. Nicola Tomatis
- ARC Seibersdorf, A, Dr. Wilfried Kubinger
- Legrand, F
- Nestlé Nespresso, CH
- Otto Bock, D
26.07.2006 XPERO
Das Experimentieren in der realen Welt ist der Schlüssel um neue Erkenntnisse zu erwerben und kognitive Fähigkeiten zu entwickeln. Je umfangreicher und lehrreicher die Experimente sind, desto umfangreicher sind die Erkenntnisse. Lernen durch experimentieren hat gegenüber anderen Lernmethoden einen wesentlichen Vorteil, nämlich dass die Lern-Ressourcen, d.h. das Lern-Material oder die Trainings-Daten grundsätzlich unbegrenzt sind.
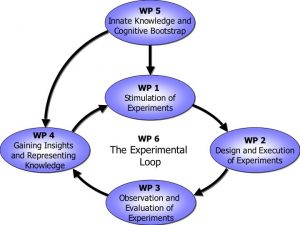
Das XPERO Konsortium vereint einige der erstklassigen europäischen Forschungsinstitutionen in folgenden Bereichen: Robotik, kognitive Systeme, kognitive Robotik, kognitives Sehen und künstliche Intelligenz.
Das allgemeine Ziel des XPERO Projekts ist ein ,,embodied“ kognitives System, welches geeignet ist in den realen Welt Experimente durchzuführen und neue Erkenntnisse über die Welt und die Objekte zu sammeln, kognitive Fähigkeiten zu entwickeln und die gesamte Leistungen zu erhöhen.
26.07.2003 NFN
„Kognitives Sehen“ – Eine Schlüsseltechnologie für persönliche Assistenzsysteme
Wir haben alle schon einmal nach persönlichen Gegenständen oder nach dem richtigen Weg in einer uns unbekannten Umgebung gesucht. Technische Lösungen einer adäquaten Hilfestellung für unsere Wahrnehmung sind noch in weiter Ferne. Der nun bewilligte FSP „Kognitives Sehen“ beschäftigt sich genau mit dieser Thematik. Der Mensch soll durch ein Sehsystem unterstützt werden, das nicht nur Dinge finden kann, sondern auch die Zusammenhänge zwischen seinen Tätigkeiten und den Dingen versteht. Dieses Verstehen von neuer Information und neuem Wissen ist der Kernpunkt des kognitiven Ansatzes der Bildverarbeitung.

Die vorgeschlagenen Lösungswege basieren auf einem trans-disziplinären Ansatz. So sind Partner eingebunden aus der theoretischen Informatik (TU Graz), Neurowissenschaft (Max-Planck-Institut Tübingen), dem maschinellen Lernen (MU Leoben) als auch der Bildverarbeitung (ACIN & PRIP and der TU Wien, EMT & ICG an der TU Graz und Joanneum Research Graz).
Ein Ansatzpunkt ist die Untersuchung des Zusammenspiels der verschiedenen Hirnregionen des Sehzentrums. Während einzelne Funktionen relativ gut untersucht sind, ermöglichen neue Analysemethoden tiefere Einblicke, die bekannte Hypothesen umstoßen. So ist für das menschliche Sehen die Erwartungshaltung enorm wichtig. Zum Beispiel werden Gegenstände, die nicht in eine Umgebung passen, sehr viel schneller erkannt als in dieser Umgebung übliche Objekte.
Aus dieser Untersuchung des einzigen „wirklich funktionierenden“ Sehsystems, werden nun Computermodelle entwickelt, um Gegenstände unter den verschiedensten Rahmenbedingungen, etwa bei Beleuchtungs-, Farb- und Formänderungen oder teilweiser Verdeckung, aber auch gegenstand-spezifische Zusammenhänge und Funktionen zu beschreiben. Ein wesentlicher Schwerpunkt ist das Erlernen dieser Modelle und Zusammenhänge. So wie man einem Kind einen neuen Gegenstand zeigt, so soll auch dem Benutzer die derzeit noch langwierige Einlernphase abgenommen werden.
Ein weiterer Ansatzpunkt der Forschungsarbeiten ist die Analyse des Zusammenspiels der einzelnen Funktionen des Sehens, insbesondere von Mechanismen zur Lenkung der Aufmerksamkeit, des Entdeckens und Identifizierens von Gegenständen, der Vorhersage von Bewegungen und Absichten des Benutzers, der Einbindung von Wissen über eine gegebene Situation, und der Entwicklung einer entsprechenden Reaktion des Systems. Die Koordination dieser Aufgaben erfolgt durch eine agenten-basierte Auslotung des Nutzens für die Gesamtfunktion.
Die entwickelten Techniken werden in Prototypen eingebaut. Ziel der nächsten drei Jahre ist es mitzuverfolgen, welche Objekte wo platziert wurden und Orte in einer bekannten Umgebung zu finden. So könnte der Benutzer das System fragen, wo sein Kaffeehäferl ist oder wo sich ein Geschäft in einer ihm nicht bekannten Strasse befindet. In beiden Fällen bekäme er Unterstützung und würde hingeführt.
26.07.2001 ActIPret
Interpreting and Understanding Activities of Expert Operators for Teaching and Education
Das Ziel des Projektes ActIPret ist die Entwicklung einer kognitiven Bildverarbeitungsmethodologie und eines entsprechenden Systems, das Aktionen einer Person, die Objekte handhabt, interpretieren und verstehen kann. Der Schwerpunkt liegt auf der aktiven Beobachtung und Interpretation der Aktionen, auf dem Unterteilen der Bildsequenzen in die zugrundeliegenden elementaren Tätigkeiten und auf der Extraktion der relevanten Aktionen und ihrer funktionellen Zusammenhänge. Das System ist aktiv in dem Sinne, da es selbständig geeignete Blickrichtungen sucht, Wissen verwendet um die Interpretationen einzuschränken und während der Beobachtung Kollisionen vermeidet. Von besonderer Bedeutung ist die Erlangung von robusten und zuverlässigen Ergebnissen durch den Einsatz von situationsbedingten Zusammenhängen und dem Wissen aus Modellen. Die robuste Wahrnehmung und Interpretation der Szenen ist die Schlüsseltechnik um die relevante Information zu gewinnen und um die beobachtete Aktion eines Experten in einer geeigneten Repräsentation (z.B., mittels Zugriff auf den Aktionsnahmen) und mit einem komfortablen Werkzeug (z.B. mit Virtual oder Augmented Reality Methoden) für einen Auszubildenden wiederzugeben.
![]()
Mit der abschließenden Begutachtung am 19. Okt. 2004 konnte das Projekt ActIPret zur Interpretation von Aktivitäten einer Person mit Objekten erfolgreich beendet werden. Die Gutachter Prof. Kostas Daniilidis (University of Pennsylvania) und Prof. Jan-Olof Eklundh (KTH, Stockholm) sowie die zuständige Kommissarin der EU Kommission Cécile Huet waren einhellig mit den erzielten Forschungsergebnissen zufrieden.
„We were very impressed by the final results, both in terms of the integration as well as the individual parts. We really praise the life demo and integration, as opposed to other projects that on wider scope end up in indefinite processing. We learned a lot about the science of vision by integrating individual components very successfully. We are really extremely happy, amazing that you did so much in three years.“
Das Projekt vereinte 5 Forschungsinstitute um automatisch zu interpretieren wann Menschen ein Objekt nehmen oder einen Knopf drücken. Dazu wurden Methoden der Bildverarbeitung verwendet um der Handbewegung zu folgen und Handgesten als auch Armgesten zu erkennen, die Gegenstände zu finden, zu erkennen und zu verfolgen, die räumlichen und zeitlichen Zusammenhänge zu analysieren und schließlich zu verwenden, um aus den Bilddaten eine verbale Abstraktion der Tätigkeit zu erhalten.
Die wichtigsten wissenschaftlichen Erkenntnisse sind:
- Aktivitäten konnten von Beispielen gelernt werden. Damit wird eine Umsetzung von Signal zu Symbol erreicht.
- Umgekehrt kann durch die Verwendung von Symbolen die Verarbeitung stark fokussiert werden und somit eine semantische Interpretation erzielt werden.
- Das Problem Symbole mit Daten zu versehen konnte auf diese Art erstmals von beiden Richtungen untersucht werden.
- Robustheit von mehrere Komponenten (Hand/Objektverfolgung und Erkennung) in beliebiger Umgebung konnte durch die Hilfe von multiplen Merkmalen erreicht werden.
- Das Werkzeug zur Integration von 10 Komponenten wird bereits in einem anderen Projekt und bei Diplomarbeiten eingesetzt.
26.07.2000 RobVision
Die Steuerung eines sechsbeinigen Roboter in einen Schiffsrumpf
Um die Teile des Schiffsrumpfes zu verschweißen und die Qualität der Schweißnaht zu prüfen, muss ein sechsbeiniger Roboter in den Schiffsrumpf navigiert werden. Da das Modell des Schiffes vorhanden ist, kann die CAD- Information verwendet werden, um den Roboter mittels eines Bildverarbeitungssystems zu ermöglichen. Die Bildverarbeitung erkennt Merkmale wie Linien, Ellipsen, Eckpunkte oder Regionen und aus der Verknüpfung mit dem CAD-Modell kann die Position und Orientierung des Roboters im Schiff laufend berechnet werden. Ein Stereo-Kamera-Kopf und eine rückwärts schauende Kamera sorgen dafür, dass der Roboter in allen Positionen genügend Merkmale in der Umgebung sehen kann. Als zukünftiger Schritt sollen die Daten zusätzlich verwendet werden, um die aktuellen Maße des Schiffes den idealen Maßen der Konstruktion gegenüberzustellen. Das Projekt hat 5 Partner aus Europa und einen kostenmäßigen Umfang von 1125 kECU, von denen die EU 750 kEURO als Förderung aufbringt.

Für weitere Informationen, bitte besuchen Sie die englischsprachige Webseite.
26.07.2000 FlexPaint
Das Ziel des Projektes FlexPaint ist der Aufbau eines Systems zur vollautomatisierten Lackierung aller Teile einer Lackierstraße. Dies gilt vor allem für Lackierstraßen mit Losgröße eins. Das heißt, dass ohne Wissen über die Art und die exakte Lage der Teile diese lackiert werden sollen. Das Projekt wird eine Lösung basierend auf Range-Sensoren und einer automatischen Bahnberechnung erarbeiten. Die technischen Probleme werden von den akademischen Partnern des Projektes gelöst. Diese haben bereits den ersten Prototyp entwickelt und getestet.
- Die Teile werden mit einem oder mehreren Range-Sensoren erfaßt.
- Aus den Punktwolken wird die Geometrie der Teile berechnet.
- Aus den Geometrievermessungen wird eine Roboterbahn für die Lackierung berechnet.
- Aus dieser Bahn wird das Programm für den Roboter erstellt.
Alle diese Schritte erfolgen vollautomatisch und das Einschreiten eines Bedieners ist nicht notwendig. Alle eintreffenden Teile können vermessen und lackiert werden. Das System arbeitet in Echtzeit. D.h., die Zykluszeit wurde so gewählt, dass die Sensorzelle direkt vor der Lackierzelle plaziert werden kann und die Geschwindigkeit des Förderbandes nicht verlangsamt werden muß.
12.06.2000 Tracking Evaluation
A Methodology for Performance Evaluation of Model-based Tracking*
Model-based object tracking has become an important means to perform robot navigation and visual servoing tasks. Until today it is still difficult to define robustness parameters which allow the direct comparison of tracking approaches and that provide objective measures of progress achieved with respect to robustness. Particularly, extensive algorithm testing is an obstacle because of the difficulty to extract ground truth. In this paper, we propose a methodology based on the evaluation of a video database which contains real-world image sequences with well-defined movements of modeled objects. It is suggested to set up and extend this database as a benchmark. Moreover, tests of the performance evaluation of the tracking system V4R (Vision for Robotics) are presented.
Video database of real-world image sequences
First image preview | Sequence description | Sequence zipped
 Gray cube moving backwards left | gray_cube1.zip
Gray cube moving backwards left | gray_cube1.zip
 Gray cube moving backwards left | gray_cube2.zip
Gray cube moving backwards left | gray_cube2.zip
 Color cube moving backwards left | color_cube3.zip
Color cube moving backwards left | color_cube3.zip
 Color cube moving backwards left | color_cube4.zip
Color cube moving backwards left | color_cube4.zip
 Color cube moving towards right | color_cube5.zip
Color cube moving towards right | color_cube5.zip
 Color cube moving towards right | color_cube6.zip
Color cube moving towards right | color_cube6.zip
 Magazine box moving backwards left | magazine_box7.zip
Magazine box moving backwards left | magazine_box7.zip
Magazine box moving backwards left | magazine_box8.zip
 Magazine box moving towards right | magazine_box9.zip
Magazine box moving towards right | magazine_box9.zip
 Magazine box moving towards right | magazine_box10.zip
Magazine box moving towards right | magazine_box10.zip
 Toy copter moving backwards left | toy_copter11.zip
Toy copter moving backwards left | toy_copter11.zip
 Toy copter moving backwards right | toy_copter12.zip
Toy copter moving backwards right | toy_copter12.zip
 Toy copter moving backwards right | toy_copter13.zip
Toy copter moving backwards right | toy_copter13.zip
* This work has been supported by the EU-Project ActIPret under grant IST-2001-32184.
12.06.2000 TOS
Trainings Optimierungs System
- Ballverfolgung
- Stereo-Bildverarbeitung
- statistische Auswertung
Beschreibung
Das Trainings-Optimierungs-System eignet sich für:
Automatisches Erfassen der Ballflugbahn mit PC-gesteuertem Zweikamerasystem Bestimmung der Ballposition auf 5cm genau und Bestimmung der Schußschärfe auf ± 1 % der Ballgeschwindigkeit.
