ARID – Autonomous Robot Indoor Dataset
The ability to recognize objects is an essential skill for a robotic system acting in human-populated environments. Despite decades of effort from the robotic and vision research communities, robots are still missing good visual perceptual systems, preventing the use of autonomous agents for real-world applications. The progress is slowed down by the lack of a testbed able to accurately represent the world perceived by the robot in-the-wild. In order to fill this gap, we introduce a large-scale, multi-view object dataset collected with an RGB-D camera mounted on a mobile robot. The dataset embeds the challenges faced by a robot in a real-life application and provides a useful tool for validating object recognition algorithms.

Fig.1: Example of RGB-D frame from the dataset with super-imposed annotation.
Dataset
In the past years, the RGB-D Object Dataset (ROD) [1] has become “de facto” standard in the robotics community for the object classification task. Despite its well-deserved fame, this dataset has been acquired in a very constrained setting and does not present all the challenges that a robot faces in a real-life deployment. In order to fill the existing gap in the robot vision community between research benchmark and real-life application, we introduce a large-scale, multi-view object dataset collected with an RGB-D camera mounted on a mobile robot, called Autonomous Robot Indoor Dataset (ARID). The data are autonomously acquired by a robot patrolling in a defined human environment. The dataset presents 6,000+ RGB-D scene images and 120,000+ 2D bounding boxes for 153 common everyday objects appearing in the scenes. Analogously to ROD, the object instances are organized into 51 categories, each containing three different object instances. In contrast, our dataset is designed to include real-world characteristics such as variation in lighting conditions, object scale, and background as well as occlusion and clutter.
A Web version of ARID, called Web Object Dataset (WOD), has been collected in order to experiment of the transferability of features from the Web domain to the robotic domain. WOD is composed of images downloaded from multiple search engines (Google, Yahoo, Bing, and Flickr) representing objects from the same categories as ARID. In order to minimize the noise while maximizing the visual variability, the images have been acquired using the method proposed by Massouh et al. [2]. The remaining noise is then manually removed, leaving a total of 50,547 samples.
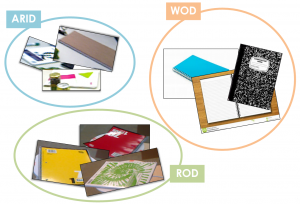
Fig.2: Examples from the three datasets ARID, ROD, and WOD from category “notebook”.
Robotic characteristics
In order to better understand which characteristics of robotic data negatively influence the results of the object classification task, we independently analyze three key variables: image dimension, occlusion, and clutter. Image dimension is a variable related to the camera-object distance: when the camera is not near enough to clearly capture the object, the object occupies only a few pixels in the whole frame, making the classification task more challenging. For obvious reasons, this problem is emphasized when dealing with small and/or elongated objects, such as dry batteries or glue sticks. Occlusion occurs when a portion of an object is hidden by another object or when only part of the object enters the field of view. Since distinctive characteristics of the object might be hidden, occlusion makes the classification task considerably more challenging. Clutter refers to the presence of other objects in the vicinity of the considered object. The simultaneous presence of multiple objects may interfere with the classification task.
Downloads
- ARID 40k Scene Dataset
Scene data corresponding to RGB, depth and pointcloud of the 40k version of the dataset; the 2D bounding box annotation for each frame is also presented as a json file. - ARID 40k Crop Dataset
Cropped objects from the 40k version of the dataset containing RGB and depth data organized according to the instance and category of the represented object. - ARID 40k Cluttered Crops
Subset of the cropped objects from the 40k version of the dataset taken from cluttered scenes. - ARID 40k Occluded Crops
Subset of the cropped objects from the 40k version of the dataset containing objects captured under occlusion or partial view. - ARID 40k Small Crops
Subset of the cropped objects from the 40k version of the dataset containing small or far objects. - Object catalog
High-resolution images representeing all the 153 objects included in the dataset. - Web Object Dataset
Web version of the dataset, representing the same 51 categories of ARID, with RGB images organized according to the category of the represented object.
Note: the full version of the dataset will be uploaded in the near future. Please notice that all the results obtained in the research paper referenced below are obtained with the 40k version, therefore they are fully reproducible with the 40k version of ARID.
Research paper
If you found our dataset useful, please cite the following paper:
@inproceedings{arid,
author = {Loghmani, Mohammad Reza and Caputo, Barbara and Vincze, Markus},
title = {Recognizing Objects In-the-wild: Where Do We Stand?},
booktitle={IEEE International Conference on Robotics and Automation (ICRA)},
year={2018}, }
Contact & credits
For any questions or issues with the dataset, feel free to contact the author:
- Mohammad Reza Loghmani – email: loghmani@acin.tuwien.ac.at
Other credits:
- Victor León: annotation of the 40k version of ARID
- Georg Halmetschlager: RGB-D camera calibration
- Silvia Bucci: WOD polishment
- Mirco Planamente: WOD polishment
References
[1] K.Lai, L.Bo, X.Ren and D.Fox, “A large-scale hierarchical multi-view rgb-d object dataset”, in Proceedings of IEEE International Conference on Robotics and Automation (ICRA), 2011, pp.1817-1824.
[2] N.Massouh, F.Babiloni, T.Tommasi, J.Young, N.Hawes and B.Caputo, “Learning deep visual object models from noisy web data: How to make it work”, CoRR, vol. abs/1702.08513, 2017