SMOT — Single sequence-Multi Objects Training
1. Introduction
The SMOT dataset, Single sequence-Multi Objects Training, is collected to represent a practical scenario of collecting training images of new objects in the real world, i.e. a mobile robot with an RGB-D camera collects a sequence of frames while driving around a table to learning multiple objects and tries to recognize objects in different locations.

Fig.1. Target Objects.
2. Training sets
The dataset consists of two training sequences that contain four target objects per sequence (total of eight objects). The image below shows the training sequences of the dataset. The poses of objects are self-annotated by a reconstruction method after defining the initial pose of each object with respect to the existing 3D models sampled from the YCB-Video dataset[1]. Note that the pose annotations are not accurate as the poses are not manually adjusted to reflect real noise that is expected when poses are annotated by a camera tracking method without strong markers.

Fig.2. Training sequences and reconstructed meshes.
3. Test sets
The test sequences are collected from three different tables and a bookshelf with different levels of clutter. An example python code that reads RGB and depth images and poses are included (io_example.py).

Fig.3. Test sequences of SMOT.

Fig.4. Visualization of GT poses in a test image. Visualizations of ground-truths for all images are included.
4. Dataset structure
- camera_intrinsic.json: camera intrinsic parameters
- /models: 3D untextured meshes of target objects
- /models_recont : 3D reconstructed meshes of target objects
- /train/seq{1~2}/
- color/, depth/: color and depth images
- scene_gt.json: gt pose information of target objects (it follows the BOP format)
- pose_vis: visualization of annotated poses (possibly have errors)
- scene_gt_cam_mat.json: camera pose per image (in 4×4 matrix, the camera coordinate at the first frame is set to the origin)
- scene_gt_cam_tum.json: camera pose per image (in TUM format, the camera coordinate at the first frame is set to the origin)
- reconstruction: a reconstructed mesh of the sequence (used to align 3D models)
- /test/seq{1~11}/
- color/, depth/: color and depth images
- scene_gt.json: gt pose information of target objects (it follows the BOP format)
- gt_vis: visualization of ground-truth poses
5. Statistics
As summarized in Table 1, the ranges of poses covered in the training set are limited compared to those of the test set. This reflects more practical cases that we have to face in the real-world.
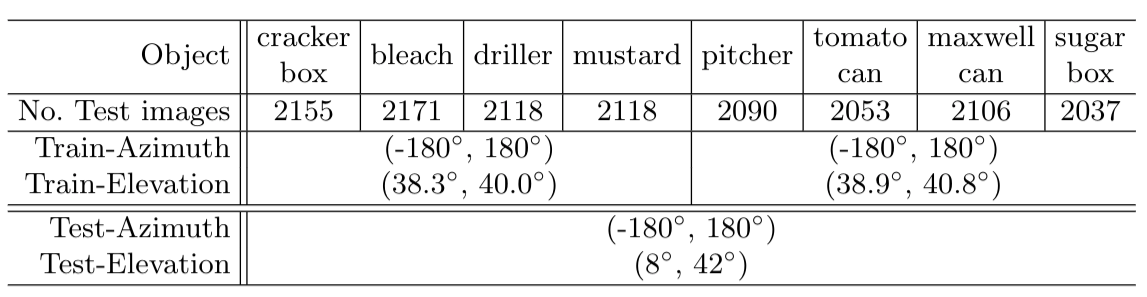
Table 1. Statistics of the dataset.
6. Download
SMOT dataset
7. Citation
If you found our dataset useful, please cite the following paper.
More details of this dataset are included in the paper and the supplementary material.
@inproceedings{Park_NOL_2019,
author={Park, Kiru and Patten, Timothy and Vincze, Markus},
title={Neural Object Learning for 6D Pose Estimation Using a Few Cluttered Images},
booktitle = {The European Conference on Computer Vision (ECCV)},
year={2020}}
8. Contact & credits
For any questions or issues with the dataset, please contact:
- Kiru Park – email: park@acin.tuwien.ac.at / kirumang@gmail.com
References
[1] B. Calli, A. Singh, J. Bruce, A. Walsman, K. Konolige, S. Srinivasa, P. Abbeel, A. M. Dollar, Yale-CMU-Berkeley dataset for robotic manipulation research, The International Journal of Robotics Research, vol. 36, Issue 3, pp. 261 – 268, April 2017.